Die Oberfläche
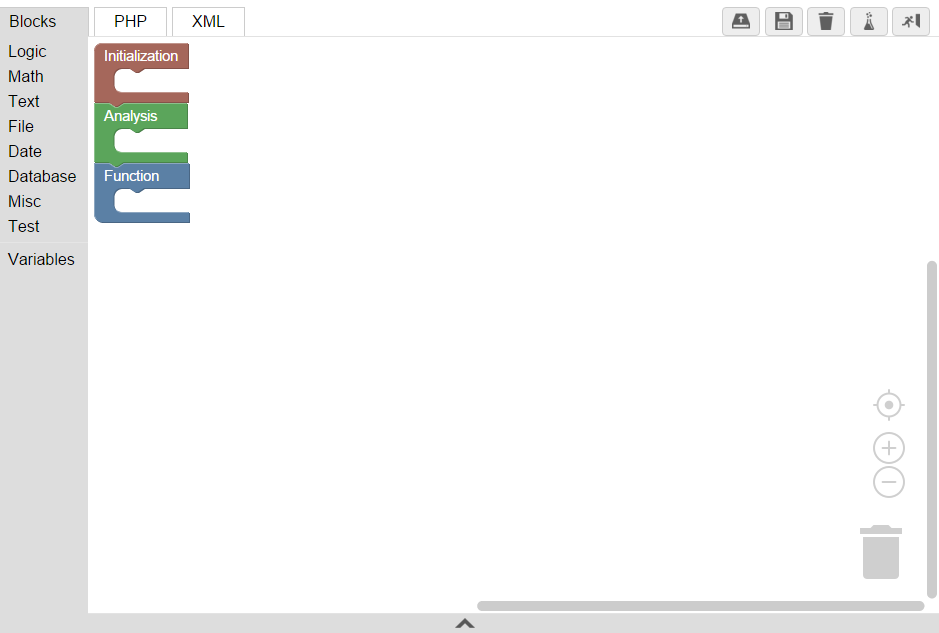
Die Oberfläche der Entwicklungsumgebung ist in zwei Hauptbereiche unterteilt. Auf der rechten Seite sehen Sie die Arbeitsfläche. Hier wird das p2fSimply-Skript zusammengebaut. Auf der rechten Seite befindet sich die sogenannte Toolbox, in der sich die verschiedenen Blöcke befinden. Durch Aufklappen der Kategorien und Herausziehen der Blöcke auf die Arbeitsfläche, können dem Skript neue Blöcke hinzugefügt werden.
Rechts unten befindet sich ein Mülleimer. Werden Blöcke auf diesem platziert, werden diese gelöscht. Darüber befinden sich eine Plus- und eine Minus-Schaltfläche, mit denen die Skalierung er Oberfläche gesteuert werden kann. Das Fadenkreuz zentriert die Ansicht auf das Skript.
Mit den Schaltflächen in der oberen rechten Ecke können (von links nach rechts) gespeicherte Skripte geladen, Skripte gespeichert, Skripte im Debugger gestartet werden und die Entwicklungsumgebung verlassen werden.
Läuft ein Skript im Debugger, klappt sich die Log-Ansicht am unteren Bildschirmrand aus und zeigt Informationen, Warnungen und Fehlermeldungen an.
Die Reiter oben links dienen zum Wechsel in andere Skriptansichten. Die PHP-Ansicht zeigt den Code, der aus dem visuellen Skript erzeugt wird. Die XML-Ansicht zeigt die interne Repräsentation des visuellen Skripts.
Die Phasen
Auf der Arbeitsfläche befinden sich bereits drei Blöcke. Das liegt daran, dass p2fSimply-Skripte eine immer wiederkehrende Struktur haben:
- Initialisierung
- Analyse der Index-Datei und Extrahierung der Daten
- Verwenden der Daten; zum Beispiel für eine Visualisierung.
Ein p2fSimply-Skript ist daher in die drei Phasen Initialization, Analysis und Function untergliedert. Diese werden durch drei Blöcke repräsentiert.
Die Analysephase stellt dabei eine Besonderheit dar und wird bei der Codegenerierung in eine Schleife übersetzt, in der die Index-Datei zeilenweise durchgegangen wird. Die in ihr befindlichen Analyseblöcke erzeugen dann If-Blöcke, welche dafür sorgen, dass ihr Code nur in jene Zeilen ausgeführt werden, die vom Nutzer angegeben wurden. Dies kann durch Zeilenindize oder auch reguläre Ausdrücke geschehen. Um vor der Analysephase noch eventuell benötige Initialisierungen von Variablen vornehmen zu können, wurde die Initialisierungsphase geschaffen. Die ist beispielsweise nützlich, wenn verschiedene Dokumenttypen von einem Skript untersucht werden. Dann kann eine Variable „Dokumenttyp“ angelegt werden und im Analyseteil abhängig von den in der Index-Datei gefundenen Daten auf einen bestimmten Wert gesetzt werden. Soll es eine Art generisches Dokument geben, dessen Typ angenommen wird, wenn keine spezifischen Daten im Dokument gefunden werden könnte dieser Typ so einfach im Initialisierungsteil voreingestellt sein.
Im Funktionsteil werden dann konkrete Aktionen mit den Daten der Index-Datei ausgelöst. So kann beispielsweise anhand der gefundenen Kundennummer die Mailadresse aus einer Datenbank abgefragt werden, die zu druckende Datei in eine PDF-Datei konvertiert werden und dann als Anhang an den Kunden per Mail gesendet werden.
Dieses Grundgerüst wurde geschaffen, um dem Nutzer eine Grundstruktur zu bieten, an der er sich orientieren kann. So muss er nicht mit einem „weißen Blatt“ beginnen. Außerdem lassen sich dadurch die Kombinationsmöglichkeiten von Blöcken einschränken, was die Erlern- und Erinnerbarkeit verbessert. Viele Skripte, die nicht wie vom Benutzer vielleicht erwartet funktionieren, lassen sich so überhaupt nicht erstellen. Die Teilung in drei Phasen ist also eine Entscheidung, um die Nutzererfahrung zu verbessern.