


Das gilt insbesondere sogar für den Fall, dass die so kodierten Binärdaten eine korrekte UTF-8 Kodierung darstellen - das wird maskiert und deshalb gar nicht erkannt!
Binärdaten in Schablonen
Anforderung
Im Zusammenhang mit dem Einsatz von Sonderzeichen in Symbolschriften oder bei der Nutzung von Barcodes kommt es immer wieder einmal vor, dass die Daten innerhalb der Schablone eines Text- oder Barocde-Feldes nicht anzeigbare Zeichen enthalten muss, die zudem über die Tastatur nicht ohne weiteres erzeugt werden können.
Bisher wurde dafür mit der Syntax '\x##' die Möglichkeit geschaffen, beliebige Werte im Bereich Hexadezimal '00' bis 'FF' in die Schablone mit aufzunehmen. Desweiteren konnten Zahlen über die Formatierung als Binärwert mit in die Schablone aufgenommen werden (siehe Tips Formatierung in Schablonen und Deutsche Post Datamatrix Code).
Mit der Umstellung von print2forms auf die Nutzung von Unicode innerhalb des Administrationsprogramms und innerhalb der Clients und Gateways birgt die Nutzung von Binärdaten aber erhebliche Riskiken für Fehlinterpretationen, die sehr oft nicht das gewünschte Druckergebnis liefern.
Deshalb ist das genaue Verständnis des Konvertierungsprozesses von Schablonen bis letztlich zum gewünschten Zielzeichensatz des Druckers von grosser Bedeutung.
Realisierung
Ab der Build-Nummer 5830 des print2forms-Clients und der Build-Nummer 3104 des print2forms-Gateways steht neben der Notation '\x##' jetzt zusätzlich die Notation '\u##' zur Verfügung. Die neue Notation liefert ebenfalls hexadezimal angegebene Werte, diese werden aber nicht als Binärdaten interpretiert, sondern als Unicode-Zeichen.
Der entscheidende Unterschied zwischen den beiden Notationen liegt darin, dass die mit '\x##' kodierten Daten nicht (!) an der Konvertierung von Unicode in den Zielzeichensatz des Druckers teilnehmen. 1) Die mit '\u##' kodierten Daten hingegen werden aber korrekt konvertiert. 2)
Die von print2forms Unicode-Zeichen liegen im Bereich von hexadezimal '20' bis 'FFFFFF'. Deshalb gibt es nicht nur die Kodierung '\u##', sondern auch '\u####' und '\u######', wobei '#' für eine beliebige Hexadezimalziffer in Gross- oder Kleinschreibung steht. Die Angabe von drei oder fünf Ziffern ist nicht erlaubt.
Basis für die Unicode-Unterstützung von print2forms ist die Schriftenbibliothek, mit der Dutzende Schriften mit tausenden von Zeichen zur Verfügung gestellt werden. So lassen viele zusätzliche Alphabete (wie Kyrillisch, Griechisch, Chinesich, Koreanisch, etc) nutzen, selbst wenn die physischen Drucker keine Unterstützung für diese Alphabete anbieten.
Bei der direkten Angabe von Unicode-Zeichen mittels '\u' innerhalb der Schablone ist zu beachten, dass sechstellige Werte grösser 'FFFF' Zeichen jenseits der BMP (Basic Multilingual Plane) adressieren. Aktuell enthält nur die Schrift Noto Sans SC noch Zeichen in der SIP (Supplementary Ideographic Plane). Sollten druckerinterne Schriften auch Zeichen aus der SMP (Supplementary Multilingual Plane) oder der TIP (Tertiary Ideographic Plane) unterstützen, können auch diese Werte angegeben werden.
Bemerkungen
- Ein besonders tückischer Fehler im hier diskutierten Zusammenhang tritt auf, wenn Binärdaten mit den Schriften aus der Schriftenbibliothek verwendet werden. War es in bisherigen Versionen von print2forms möglich, z.B. ein Piktogramm aus einer Symbolschrift, das auf dem Grossbuchstaben 'U' lag, als '\x55' zu schreiben, geht das jetzt nicht mehr. Der Grund liegt darin, dass das Zeichen für das binär kodierte 'U' nicht als druckbares Zeichen erkannt wird, und infolgedessen von der Schriftverwaltung nicht in den Druckerspeicher geladen wird. Daher muss in diesen Fällen unbedingt '\u55' zur Anwendung kommen, weil nur dann das Unicode-Zeichen tatsächlich als 'U' erkannt und in den Druckerspeicher geladen wird.
- Die Notation '\u##' sollte der Kodierung von ganz besonderen Unicode-Zeichen vorbehalten sein. Die Hexadezimalzahlen sind nicht wirklich selbsterklärend, und lassen im Dunkeln, was hier ausgegeben werden soll. Ist im Administrationsprogramm eine Schrift mit grossem Zeichenumfang ausgewählt, z.B. Arial Unicode oder Deja Vu Sans, können Unicode-Zeichen auch direkt eingegeben und angezeigt werden:
|
|
|
|
- Ein Tip: Das rechte Panel im Administrationsprogramm ist in Wirklichkeit ein Browser-Fenster. Von daher kann es mit Strg-Plus und Strg-Minus vergrössert und verkleinert werden. Auch die Nutzung des Scrollrades bei gedrückter Alt-Taste wird unterstützt. 3) Damit lassen sich sehr kleine, kaum lesbare Zeichen in der Darstellung beliebig vergrössern:
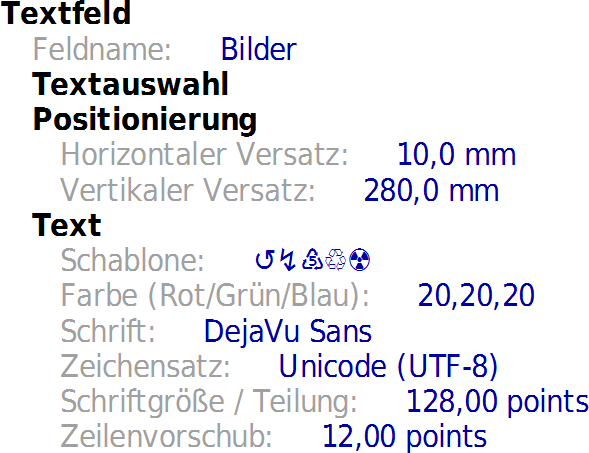
2)
Die Unicode-Zeichen werden von print2forms intern automatisch in UTF-8 Sequenzen konvertiert. Es ist also so, dass mit '\u##' tatsächlich der Unicode-Codepoint angegeben wird, und nicht etwa seine UTF-8 Kodierung! Diese Codepoints können den Zeichentabellen der Schriften aus der Bibliothek entnommen werden, oder, wenn Zugriff besteht, der Unicode-Spezifikation ISO 10646.
3)
Strg-Null stellt die Darstellungsgrösse wieder auf den Normalzustand zurück!
print2forms/tips/tip86.txt · Zuletzt geändert: 2022-03-24 16:59 (Externe Bearbeitung)